Speed Up Your API Requests With Thread Pools
APIs have become an integral part of Data Science and the development of web applications. However retrieving large quantities of data from APIs can be incredibly time-consuming. If you are trying to put your Data Science projects into production, these long wait times are unacceptable. In this article, I’ll go over Thread Pools and how to use them to speed up your API requests.
Overview & Setup
I’m an investor so I often need to retrieve financial data from APIs to analyze the market. I’ll be going over a simple example of how to pull data from the Yahoo Finance API and calculate the Free Cash Flow of several mining companies — first normally, then with Thread Pools.

If you would like to follow along in a Jupyter notebook, you can start by downloading yahoofinancials, a Python package that makes interacting with the Yahoo Finance API easy.
!pip install yahoofinancialsDepending on your environment, you may have to install pandas as well. We’ll be using the concurrent package too (which we’ll talk about later), but that package comes with Python.
Normal API Requests
If we were to visualize what we’d normally do to retrieve data from an API, it might look something like the image below. We have multiple tasks (red circles) in the Task Queue on the left. Think of these as functions waiting to make API requests. Then, once the API request is made and the data is retrieved, the green circle moves to the Completed Tasks section on the right.

This one-by-one method of retrieving data from APIs is what can become time-consuming.
To make this concept more concrete, let’s use a bit of Python code to build a function that makes requests from the Yahoo Finance API. Let’s start by importing the packages we need for this example.
from yahoofinancials import YahooFinancials
import pandas as pd
import concurrent.futuresNow let’s build a function that retrieves Total Cash from Operating Expenses and Capital Expenditures, then subtracts capex from total cash to get Free Cash Flow.
def calculate_fcf(ticker): # make yahoofinancials instance
yahoo_financials = YahooFinancials(ticker) # get date for the last quarter reported
last_quarter_reported = next(iter(yahoo_financials.get_financial_stmts(‘quarterly’, ‘cash’[‘cashflowStatementHistoryQuarterly’][ticker][0])) # get total cash from operating activities
tcfoa = yahoo_financials.get_financial_stmts(‘quarterly’, ‘cash’)[‘cashflowStatementHistoryQuarterly’][ticker][0][last_quarter_reported][‘totalCashFromOperatingActivities’] # get capital expenditures
capex = yahoo_financials.get_financial_stmts(‘quarterly’, ‘cash’)[‘cashflowStatementHistoryQuarterly’][ticker][0][last_quarter_reported][‘capitalExpenditures’] # get free cash flow
fcf = tcfoa — abs(capex) # return date of last quarter reported and free cash flow
return last_quarter_reported, fcf
(Note: Sorry about the weird formatting. If you copy-paste into Jupyter it should come out okay.)
Now let’s loop over each stock ticker and use the function above to calculate Free Cash Flow for each mining company.
%%timetickers = [‘NEM’, ‘FCX’, ‘BBL’, ‘GLNCY’, ‘VALE’, ‘RTNTF’, ‘SCCO’, ‘AU’, ‘NGLOY’, ‘HL’] #ticker listquarter_dates = [] # list to store quarter dates
fcfs = [] # list to store free cash flows
for ticker in tickers: # loop through tickers list
calc_fcf = calculate_fcf(ticker) # use function for API request
quarter_date = calc_fcf[0] # get date element from function
fcf = calc_fcf[1] # get fcf element from function # append results to lists
quarter_dates.append(quarter_date)
fcfs.append(fcf)
Think of each potential ticker-function combination in the loop as a red circle in the Tasks Queue above. Once the API request for each ticker is made, it takes time to retrieve the data (think of the red circle changing to green in the image above). Then, when the data is fully retrieved and stored in the lists (i.e. memory), the green circle moves to the Completed Tasks section in the image above.
If you’re following along in Jupyter, you’ll notice the “%%time” at the top of the code cell. This measures how long it took to run the code. It took 1 minute and 12 seconds to complete all tasks.

API Requests with Thread Pools
Let’s now use a Thread Pool to drastically improve this time. A Thread Pool will allow us to use multiple ‘workers’ to make concurrent API requests. If we have less workers than tasks in the Task Queue, a task will be sent to the Thread Pool as soon as an open space is available.

We’ll use ThreadPoolExecutor() from the concurrent package to rework our Python code.
%%timewith concurrent.futures.ThreadPoolExecutor() as executor: tickers = [‘NEM’, ‘FCX’, ‘BBL’, ‘GLNCY’, ‘VALE’, ‘RTNTF’, ‘SCCO’, ‘AU’, ‘NGLOY’, ‘HL’] # ticker list results = executor.map(calculate_fcf, tickers) # map takes the function and iterables quarter_dates = [] # list to store quarter dates
fcfs = [] # list to store free cash flows
for result in results: # loop through results
quarter_dates.append(result[0]) # append date element
fcfs.append(result[1]) # append fcf element
Instead of going straight to the for loop like in the first example, we obtain the results with ThreadPoolExecutor’s map function, where we pass the calculate_fcf function and the iterables (list of stock tickers). Then we loop through the results to get the data.
Let’s see how long this took.

We went from over 1 minute to 9 seconds. The Thread Pool makes a huge difference!
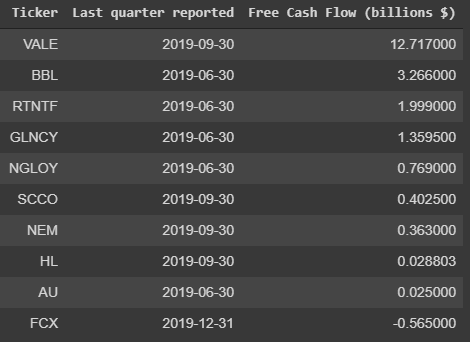
With quick use of pandas, our data is ready to be analyzed.
df = pd.DataFrame({‘Ticker’: tickers,’Last quarter reported’: quarter_dates, ‘Free Cash Flow’: fcfs})df = df.sort_values(by=[‘Free Cash Flow’], ascending=False)df[‘Free Cash Flow’] = df[‘Free Cash Flow’] / 1000000000df = df.rename(columns={‘Free Cash Flow’: ‘Free Cash Flow (billions $)’})
Summary
Thread Pools can be used for much more than API requests. It is a common tool used to speed up software. This is simply a very practical use of Thread Pools for myself. And I thought it could be a practical or helpful guide for others.
Thread Pools are used for much more than API requests, but they are not good for everything. If you are doing something computationally expensive, you may need multiprocessing instead.
Also, it may be tempting to max out workers when using Thread Pools, but there are diminishing returns. Here’s an article from a Microsoft Engineer on why not to use too many workers.
Thanks for reading and feel free to leave comments.